前言
今年,我参加学校举办的的一个嵌入式比赛,我的作品中需要用到中文文本语音转换的功能,由于是使用linux系统,所以不能使用MS提供的语音开发包,虽然linux上也有很多TTS功能的软件,但都只支持英语文本的转换,不支持中文的转换,当然支持中文语音转换的也有,但都需要money的,而且我们对语音的要求不高,所以就由我自己来实现。
我实现的中文TTS现有功能如下:
- 基于中文二级字库,语音库的语音元素使用的是MS的语音库语音元素。
- 合成语音文件的格式为 WAV,所以合成语音可以直接在声卡上播放。
- 提供简单的函数调用接口,支持程序开发
附:
我实现的中文TTS 需改进的N点:
- 没有自己的语音播放功能(我是FORK 播放器进程来读语音文件的)需要在TTS中增加播放功能模块,才能算是完整的TTS系统,网上有很多LINUX上播放器的代码,由于时间关系我暂时没做,但以后我一定会加上去的,我也希望能有朋友能帮我完成这功能
- 语音库文件太大(没压缩前有40M左右,使用普通的压缩程序压缩后只有2M多点)我的发音元素是采用WAV格式的,所以有点大, 解决方法我暂时还没想到,我打算对压缩文件进行操作,但不知道行不行,自己没把握。
- 提供的函数功能太简单
3.1): 现在只提供了将GBK/GB2312编码 的中文文本转换, 如果程序使用的编码是其它格式的话,还需先自己转换成GBK/GB2312的编码 才能使用我提供的函数,我想在中文TTS中封装编码转换函数,这样能使应用程序更方便的使用。
3.2): 其他很多功能的实现:
太多功能需要来实现,写都写不来了。。比如说读数字的处理等等,太多了,所以暂时空着
- 读音效果
我想这点应该是评价一个TTS系统的最关键的因素,也是我自己认为最难的一点,我想这可能超出了我的知识范围,我的头脑中只存在着编程逻辑,对其他的知道得甚少,我想我自己得突破这点。了解其它学科的知识。 现在我只能说一句, 现在的读音效果超差,一听就知道是机器在读,没有一点人情味。
- 不支持中英文混读
现在只能读中文,英文是一个一个字母的读,虽然有很多关于英语转换的TTS软件是开源的,但要完成这功能还是需要一定的工作量的,想想如果让我一个人来做,就头晕,天哪,要看N多的代码.......
- 多音字的处理
我想这可能要用到中文分词了....
实现原理
采用波形拼接的语音生成方法来实现本系统。这种方法预先建立一个庞大的语音数据库,在合成时采用恰当的技术手段挑选出所需的语音基元进行拼接,从而形成语音输出。因此,语音拼接的重点是基本语音单元的拼接,我们选取字作为基本的语音拼接单位,语音数据库由若干以字为单位的WAV样本文件组成。[1]
所以实现本汉语TTS系统主要完成两项工作:
第一:建立一个语音库,语音库中记录了普通话中所有汉字的读音;
第二:建立汉字机内码到汉字读音的访问方法,实现由输人的汉字机内码得到该汉字的读音。并且合成WAV声音文件。[2]
语音库的实现
语音库保存着常用汉字的发音(多音的汉字只记录其一种发音,这也是本系统的一个缺陷,需要以后完善),所以先要得到一汉字集,这个汉字集包含了大部分常用的汉字,然后在根据这个汉字集,来一个个的取得汉字的发音,并且按一定的规则保存到语音库中。
所以实现语音库可以分为三步:
- 取得常用汉字的集合
- 根据汉字集,使用一些朗读软件生成该汉字集的语音文件
- 处理汉字集语音文件的格式,使它能符合我们的要求
1.1根据汉字编码规则获取汉字字符集的文本文件
1.1.1编码知识:
所谓编码,是以固定的顺序排列字符,并以此作为记录、存贮、传递、交换的统一内部特征。一个汉字有ASC II码、区位码等与之对应。ASC II码中对应于码值161到254的字符用于表示汉字,每个汉字用两个ASC1I码值对应的字符表示。区位码用4位数字表示,前两位从01到94称区码,后两位从01到94称位码。一个汉字的前一半是 ASC II码为“160+区码”的字符,后一半是ASCII码为“160+位码”的字符。例如:“刘”的区位码是3385,其意为区码33和位码85,它是由 ASCII码为160+33=193和160+85=245的两个字符组成。
该文所说的汉字字符集一般是指ISO 10646.1 即GB13000.1。在Windows 95/98/2000中,微软提供了“汉字扩展内码规范(GBK)”以解决汉字的收字不足、简繁共存、简化代码体系间转换等汉字信息交换的瓶颈问题,利用 GBK可以方便解决“镕”、“薯”等大量汉字的交换问题而不必自行造字了。GBK字库共分为5部分,其中GBK/1和GBK/5为符号部分,GBK/2为国标汉字部分,GBK/3和GBK/4为扩展汉字部分。其中,第16区至55区为一级汉字,以拼音排序,共计3755字,56—87区为二级汉字,按偏旁部首排序,共计3008字。
1.1.2程序代码:
用C++实现的获取GBK中一级汉字字符的代码段如下:
//getgbk.cpp一获取GBK汉字码文件
#include
#include
unsigned char oneline[4];
ofstream ofs("gbhz.txt",ios::binary );
oneline[2]=163;
oneline[3]=172;
int qm;
int wm;
for( qm=176;qm<=247;qm++)//区码0XB0—0XD7 87
for(wm=161;wm<=254;wm++) //位码0XA1—0XFE
if(!((qm==247)&&(wm=250)))
//剔除GBK中没有编码的字位
{
oneline[0]=qm; //汉字区码
oneline[1]=wm; //汉字位码
ofs.write((char *)&oneline,4); //写一行至gbhz txt
}//if end
1.2:根据取得的汉字集,使用一些报读软件生成该汉字集的语音文件,一般为WAV格式的。这里取名为gbhz.wav
1.3:处理汉字集读音文件的格式
1.3.1 理解WAV文件格式
WAVE文件作为多媒体中使用的声波文件格式之一.它是以RlFF格式为标准的 每个wAVE文件的头4个字节便是“RIFF” WAVE文件由文件头和数据体两大部分组成。其中文件头又分为RIFE/WAV文件标识段和声音数据格式说明段两部分 。WAVE文件格式说明见下表,
|
内容 |
数据类型 |
字节数 |
|
“RIFF”标志 |
Char |
4Byte |
|
文件大小 |
Long int |
4Byte |
|
“wave”标志 |
Char |
4Byte |
|
“fmt”标志 |
Char |
4Byte |
|
PCMWAVFORMAT数据结构大小 |
Long int |
4Byte |
|
PCMWAVFORMAT数据结构 |
||
|
“data”标志 |
Char |
4Byte |
|
语音数据大小 |
Long int |
4Byte |
可以以时域-幅度的方式显示出原始声音的波形,这是最简单同时也是最直接的信息处理方式。在时域范国内,可以观察该信号波形是否连续,中间是否有祧变等。据发现,经语音引擎处理后,每个汉字所对应的语音数据长度不尽相同.这给以后截取每个汉字的语音数据造成了困难。因此.为了区分每个汉宇的语音数据.在生成汉字字符集时.在每个汉字后添加了一个逗号作为闻隔符 这样生成的语音文件的波形图(部分)如图1所示

1.3.2生成新的汉字字符集的话音文件的算法
(1)打开gbhz.wav.从gbhz.wav中读人文件头CHAR HEAD[46]。46为文件头长度。
(2)从gbhz.wav 中读入第一个汉字的语音波形数据放入CHAR BUFFER[3200]。3200为一个汉字的语音波形数据长度.选取决于形成语音的速率、音质等因素
(3)读后面的数据,如果是0x80则不做处理.继续往后读。ox80是逗号语音数据,既没有发音的数据。
(4)直到读到第一个不是逗号的语音数据,开始记录第二个汉字的语音波形数据到CHAR BUFFER[3200]
(5)重复3.4步直到读完全部的语音波形数据。
合成新的汉字字符集的语音文件后的波形图(部分)如图2所示

1.3.3 处理代码如下:
#defineMAXLEN32000
int HandingWav()
{
FILE * fpf,*fpt; //文件操作指针
if((fpf=fopen("gbhz.wav","rb+"))==NULL)//gbhz.wav为处理前的语音文件
return -1;
if((fpt=fopen("ddd.wav","rb+"))==NULL)//ddd.wav为合成的新的语音文件
return -1;
char head[46];//wav文件的文件头长度
char data[100];//用来加速文件处理的数组
char buffer[MAXLEN];
memset(buffer,0,MAXLEN);
fread(head,sizeof(head),1,fpf);//head of wav
fwrite(head,sizeof(head),1,fpt);
while(!feof(fpf))
{
fread(buffer,MAXLEN,1,fpf);//读一个字的发音
fwrite(buffer,MAXLEN,1,fpt);//写一个字
memset(buffer,0,MAXLEN);
fread(data,1,1,fpf); //读一个字节
while(data[0]==char(0x80)) //判断是否为0x80
{
if(fread(data,100,1,fpf)==-1) //每次取100个字节,但只判断第一个字节,这样可以加速文件处理
{
fclose(fpf);
fclose(fpt);
return -1;
}//end if
}//end while判断是否为0x80
}// end while(!feof(fpf))
fclose(fpf);//关闭文件
fclose(fpt);
return 0;
}
经过以上的操作后,就形成了我们所要的语音库了。
实现语音合成
合成语音归根到底是根据汉字在字符集的定位来取语音库中的数据
定位方法:
根据救字的两个字节中的值.从高字节算出汉字的位wm.从低字节算出汉字的区qm,(qm一176)*94+wm一160就是该况字在汉字集里的位置position,而该汉字所对应的语音数据的偏移量就是(position一1) 3200+46。
根据定位方法取得汉字在语音库中的发音数据后,根据WAV格式合成语音文件。
定位和合成代码如下:
#define MAXLEN32000
/*
参数str:为纯汉字的字符串,且编码格式为GBK
返回值:
-1:表示语音库文件打开错误
-2:表示合成语音文件 打开/生成错误
其它:函数执行成功
*/
intwav(char *str)
{
FILE * fpf,*fpt;//文件指针
int qm,wm;//汉字区、位码
int re;//函数返回值
long fileleng=0;//文件长度 后面修改WAV格式时有用
if((fpf=fopen("ddd.wav","rb+"))==NULL)//打开语音库文件
return -1;
if((fpt=fopen("china.wav","wb+"))==NULL)//打开或生成合成后的语音文件,用来播放的
return -2;
char head[46];//WAV 文件头
char buffer[MAXLEN];//发音数据BUFF
memset(buffer,0,MAXLEN);//置0
fread(head,sizeof(head),1,fpf);//读语音库文件头
fwrite(head,sizeof(head),1,fpt);//写入合成语音文件
int l=strlen(str);
char *s=str;
for(int i=0;i<=l;i=i+2)
{
qm=(unsigned char)*(s+i);//取汉字的区码
wm=(unsigned char)*(s+1+i);//取汉字的位码
if (qm<176||qm>215)//判断是否在汉字字符集中
continue;
if (wm<161||wm>254)//判断是否在汉字字符集中
continue;
int position =(qm-176)*94+wm-160;
int offset=(position-1)*MAXLEN+46;//定位
fseek(fpf,offset,0);
fread(buffer,sizeof(buffer),1,fpf);//取发音数据
fwrite(buffer,sizeof(buffer),1,fpt);//写入合成文件
fileleng++;//合成文件长度增加
}//end for
re =fileleng;
fileleng=fileleng*MAXLEN;
fseek(fpt,42,SEEK_SET);
fwrite(&fileleng,sizeof(long),1,fpt);//修改合成文件的WAV格式,主要是修改文件大小,具体请看WAV格式表
fileleng+=44;
fseek(fpt,4,SEEK_SET);
fwrite(&fileleng,sizeof(long),1,fpt);//修改合成文件的WAV格式,主要是修改文件大小,具体请看WAV格式表
fclose(fpf);//关闭文件
fclose(fpt);
return re;
}
其它:
由函数WAV可以看出,我们接收用户的输入字符的编码必须为GBK编码,所以如果系统使用的不是 GBK编码的话,我们还应当进行编码转换。如果编码正确的话,还得从把用户的输入中把中文字符给提取出来。为此,我写了小段代码,用来过滤非中文字符的。
void trans(char *str)
{
int i = 0, j = 0;
while( str[i] != '\0' )
{
if ( str[i] < 0 )
{
str[j++] = str[i++];
str[j++] = str[i++];
}
else
i++;
}//end while
str[j] = '\0';
}
后记:
采用波形拼接的方法有个很大的缺点,就是使用的语音库文件太大,而且多音节字根本无法解决。还有一种实现中文TTS方法就是记录全部的发音,因为在普通话中,实际存在的发音只有1333种。所以我们的语音库只要保存这1333个语音就行,而不需要保存每个汉字的读音。如果语音库只有1333个读音的话,我们还得建立索引表来记录每个汉字在语音库中的位置,因为有了索引表,就可以解决多音汉字的问题,由于涉及到多音汉字发音的识别,还得用到分词技术。关于分词技术朋友们可以看下 http://www.nlp.org.cn/。
关于takaya朋友问的实现自然连续的发音问题:
说实话,这是我最想解决和实现的问题,我自己想了下,如果以词组为单位来做语音库,那声音听起来就比较连续,因为我们平时说话 也是以词组为单位说的,但如果要实现这个的话,就得用到分词技术,而且语音库的建立也要一定的功夫。
白: 我一直是以程序员的角度去做这个简单的TTS的,所以很多东西我自己也有误解或不懂的地方,希望朋友们不要笑话我,并且能帮我提出问题和指导我。
这个TTS还有很多很多如前言列出的需要改进的地方,我希望能有这方面爱好的朋友能我和一起来完善它。
期待ing...
参考文献:
1郭兰英. 汉语语音拼接技术的研究. 计算机应用软件第22卷第11期
2袁嵩. 一个TTS系统的实现方案. 计算机工程与应用2004.21 229
-
 热敏电阻温度阻值查询程序2024年11月13日 74
热敏电阻温度阻值查询程序2024年11月13日 74 -
C99语法规则2024年11月16日 675
-
 FreeRTOS 动态内存管理2024年11月12日 448
FreeRTOS 动态内存管理2024年11月12日 448 -
一款常用buffer程序2024年11月06日 88
-
 1602液晶显示模块的应用2012年08月03日 192
1602液晶显示模块的应用2012年08月03日 192 -
GNU C 9条扩展语法2024年11月18日 261
-
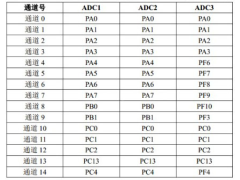 如何实现STM32F407单片机的ADC转换2024年11月15日 300
如何实现STM32F407单片机的ADC转换2024年11月15日 300 -
 STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
-
C99语法规则2024年11月16日 675
-
 51单片机LED16*16点阵滚动显示2012年09月05日 664
51单片机LED16*16点阵滚动显示2012年09月05日 664 -
FreeRTOS 动态内存管理2024年11月12日 448
-
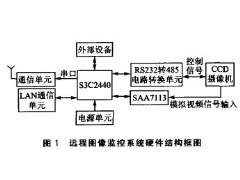 ARM9远程图像无线监控系统2012年07月03日 424
ARM9远程图像无线监控系统2012年07月03日 424 -
 用单片机模拟2272软件解码2012年09月06日 300
用单片机模拟2272软件解码2012年09月06日 300 -
如何实现STM32F407单片机的ADC转换2024年11月15日 300
-
 新颖的单片机LED钟2012年08月06日 278
新颖的单片机LED钟2012年08月06日 278 -
GNU C 9条扩展语法2024年11月18日 261