小弟最近研究了一段时间的ARM Linux,想把进程管理方面的感受跟大家交流下,不对的地方多多指点
Process Creation and Termination
Process Scheduling and Dispatching
Process Switching
Porcess Synchronization and support for interprocess communication
Management of process control block
--------from
进程调度
Linux2.4.x是一个基于非抢占式的多任务的分时操作系统,虽然在用户进程的调度上采用抢占式策略,但是而在内核还是采用了轮转的方法,如果有个内核态的线程恶性占有CPU不释放,那系统无法从中解脱出来,所以实时性并不是很强。这种情况有望在Linux 2.6版本中得到改善,在2.6版本中采用了抢占式的调度策略。
内核中根据任务的实时程度提供了三种调度策略:
- SCHED_OTHER为非实时任务,采用常规的分时调度策略;
- SCHED_FIFO为短小的实时任务,采用先进先出式调度,除非有更高优先级进程申请运行,否则该进程将保持运行至退出才让出CPU;
- SCHED_RR任务较长的实时任务,由于任务较长,不能采用FIFO的策略,而是采用轮转式调度,该进程被调度下来后将被置于运行队列的末尾,以保证其他实时进程有机会运行。
需要说明的是,SCHED_FIFO和SCHED_RR两种调度策略之间没有优先级上的区别,主要的区别是任务的大小上。另外,task_struct结构中的policy中还包含了一个SCHED_YIELD位,置位时表示该进程主动放弃CPU。
在上述三种调度策略的基础上,进程依照优先级的高低被分别调系统。优先级是一些简单的整数,它代表了为决定应该允许哪一个进程使用CPU的资源时判断方便而赋予进程的权值——优先级越高,它得到CPU时间的机会也就越大。
在Linux中,非实时进程有两种优先级,一种是静态优先级,另一种是动态优先级。实时进程又增加了第三种优先级,实时优先级。
- 静态优先级(priority)——被称为“静态”是因为它不随时间而改变,只能由用户进行修改。它指明了在被迫和其它进程竞争CPU之前该进程所应该被允许的时间片的最大值(20)。
- 动态优先级(counter)——counter 即系统为每个进程运行而分配的时间片,Linux兼用它来表示进程的动态优先级。只要进程拥有CPU,它就随着时间不断减小;当它为0时,标记进程重新调度。它指明了在当前时间片中所剩余的时间量(最初为20)。
- 实时优先级(rt_priority)——值为1000。Linux把实时优先级与counter值相加作为实时进程的优先权值。较高权值的进程总是优先于较低权值的进程,理L垠I-;供Yo6网n,如果一个进程不是实时进程,其优先权就远小于1000,所以实时进程总是优先。
在每个tick到来的时候(也就是时钟中断发生),系统减小当前占有CPU的进程的counter,如果counter减小到0,则将need_resched置1,中断返回过程中进行调度。update_process_times()为时钟中断处理程序调用的一个子函数:
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id(), system = user_tick ^ 1;
update_one_process(p, user_tick, system, cpu);
if (p->pid) {
if (--p->counter <= 0) {
p->counter = 0;
p->need_resched = 1;
}
if (p->nice > 0)
kstat.per_cpu_nice[cpu] += user_tick;
else
kstat.per_cpu_user[cpu] += user_tick;
kstat.per_cpu_system[cpu] += system;
} else if (local_bh_count(cpu) || local_irq_count(cpu) > 1)
kstat.per_cpu_system[cpu] += system;
}
Linux中进程的调度使在schedule()函数中实现的,该函数在下面的ARM汇编片断中被调用到:
/*
* This is the fast syscall return path.We do as little as
* possible here, and this includes saving r0 back into the SVC
* stack.
*/
ret_fast_syscall:
ldrr1, [tsk, #TSK_NEED_RESCHED]
ldrr2, [tsk, #TSK_SIGPENDING]
teqr1, #0@ need_resched || sigpending
teqeqr2, #0
bne slow
fast_restore_user_regs
/*
* Ok, we need to do extra processing, enter the slow path.
*/
slow:strr0, [sp, #S_R0+S_OFF]!@ returned r0
b1f
/*
* "slow" syscall return path."why" tells us if this was a real syscall.
*/
reschedule:
blSYMBOL_NAME(schedule)
ENTRY(ret_to_user)
ret_slow_syscall:
ldrr1, [tsk, #TSK_NEED_RESCHED]
ldrr2, [tsk, #TSK_SIGPENDING]
1:teqr1, #0@ need_resched => schedule()
bne reschedule@如果需要重新调度则调用schedule
teqr2, #0@ sigpending => do_signal()
blne__do_signal
restore_user_regs
而这段代码在中断返回或者系统调用返回中反复被调用到。
1. 进程状态转换时: 如进程终止,睡眠等,当进程要调用sleep()或exit()等函数使进程状态发生改变时,这些函数会主动调用schedule()转入进程调度。
2. 可运行队列中增加新的进程时;
ENTRY(ret_from_fork)
blSYMBOL_NAME(schedule_tail)
get_current_task tsk
ldrip, [tsk, #TSK_PTRACE]@ check for syscall tracing
mov why, #1
tstip, #PT_TRACESYS@ are we tracing syscalls?
beq ret_slow_syscall
mov r1, sp
mov r0, #1@ trace exit [IP = 1]
blSYMBOL_NAME(syscall_trace)
bret_slow_syscall@跳转到上面的代码片断
3. 在时钟中断到来后:Linux初始化时,设定系统定时器的周期为10毫秒。当时钟中断发生时,时钟中断服务程序timer_interrupt立即调用时钟处理函数do_timer( ),在do_timer()会将当前进程的counter减1,如果counter为0则置need_resched标志,在从时钟中断返回的过程中会调用schedule.
4. 进程从系统调用返回到用户态时;判断need_resched标志是否置位,若是则转入执行schedule()。系统调用实际上就是通过软中断实现的,下面是ARM平台下软中断处理代码。
.align5
ENTRY(vector_swi)
save_user_regs
zero_fp
get_scno
enable_irqs ip
strr4, [sp, #-S_OFF]!@ push fifth arg
get_current_task tsk
ldrip, [tsk, #TSK_PTRACE]@ check for syscall tracing
bicscno, scno, #0xff000000@ mask off SWI op-code
eorscno, scno, #OS_NUMBER << 20@ check OS number
adrtbl, sys_call_table@ load syscall table pointer
tstip, #PT_TRACESYS@ are we tracing syscalls?
bne __sys_trace
adrsvcal, lr, ret_fast_syscall@ 装载返回地址,用于在跳转调用后返回到
@上面的代码片断中的ret_fast_syscall
cmp scno, #NR_syscalls@ check upper syscall limit
ldrccpc, [tbl, scno, lsl #2]@ call sys_* routine
add r1, sp, #S_OFF
2:mov why, #0@ no longer a real syscall
cmp scno, #ARMSWI_OFFSET
eorr0, scno, #OS_NUMBER << 20 @ put OS number back
bcsSYMBOL_NAME(arm_syscall)
bSYMBOL_NAME(sys_ni_syscall)@ not private func
5. 内核处理完中断后,进程返回到用户态。
6. 进程主动调用schedule()请求进行进程调度。
schedule()函数分析:
/*
* 'schedule()' is the scheduler function. It's a very simple and nice
* scheduler: it's not perfect, but certainly works for most things.
*
* The goto is "interesting".
*
* NOTE!!Task 0 is the 'idle' task, which gets called when no other
* tasks can run. It can not be killed, and it cannot sleep. The 'state'
* information in task[0] is never used.
*/
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
struct list_head *tmp;
int this_cpu, c;
spin_lock_prefetch(&runqueue_lock);
if (!current->active_mm) BUG();
need_resched_back:
prev = current;
this_cpu = prev->processor;
if (unlikely(in_interrupt())) {
printk("Scheduling in interrupt\n");
BUG();
}
release_kernel_lock(prev, this_cpu);
/*
* 'sched_data' is protected by the fact that we can run
* only one process per CPU.
*/
sched_data = & aligned_data[this_cpu].schedule_data;
spin_lock_irq(&runqueue_lock);
/* move an exhausted RR process to be last.. */
if (unlikely(prev->policy == SCHED_RR))
/*
* 如果采用轮转法调度,则重新检查counter是否为0, 若是则将其挂到运行队列的最后
*/
if (!prev->counter) {
prev->counter = NICE_TO_TICKS(prev->nice);
move_last_runqueue(prev);
}
switch (prev->state) {
case TASK_INTERRUPTIBLE:
/*
* 如果是TASK_INTERRUPTIBLE,并且能够唤醒它的信号已经来临,
* 则将状态置为TASK_RUNNING
*/
if (signal_pending(prev)) {
prev->state = TASK_RUNNING;
break;
}
default:
del_from_runqueue(prev);
case TASK_RUNNING:;
}
prev->need_resched = 0;
/*
* this is the scheduler proper:
*/
repeat_schedule:
/*
* Default process to select..
*/
next = idle_task(this_cpu);
c = -1000;
list_for_each(tmp, &runqueue_head) {
/*
* 遍历运行队列,查找优先级最高的进程, 优先级最高的进程将获得CPU
*/
p = list_entry(tmp, struct task_struct, run_list);
if (can_schedule(p, this_cpu)) {
/*
* goodness()中,如果是实时进程,则weight = 1000p->rt_priority,
* 使实时进程的优先级永远比非实时进程高
*/
int weight = goodness(p, this_cpu, prev->active_mm);
if (weight > c)//注意这里是”>”而不是”>=”,如果权值相同,则先来的先上
c = weight, next = p;
}
}
/* Do we need to re-calculate counters? */
if (unlikely(!c)) {
/*
* 如果当前优先级为0,那么整个运行队列中的进程将重新计算优先权
*/
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);
read_lock(&tasklist_lock);
for_each_task(p)
p->counter = (p->counter >> 1)NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
goto repeat_schedule;
}
/*
* from this point on nothing can prevent us from
* switching to the next task, save this fact in sched_data.
*/
sched_data->curr = next;
task_set_cpu(next, this_cpu);
spin_unlock_irq(&runqueue_lock);
if (unlikely(prev == next)) {
/* We won't go through the normal tail, so do this by hand */
prev->policy &= ~SCHED_YIELD;
goto same_process;
}
kstat.context_swtch;
/*
* there are 3 processes which are affected by a context switch:
*
* prev == .... ==> (last => next)
*
* It's the 'much more previous' 'prev' that is on next's stack,
* but prev is set to (the just run) 'last' process by switch_to().
* This might sound slightly confusing but makes tons of sense.
*/
prepare_to_switch();{
struct mm_struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if (!mm) {//如果是内核线程的切换,则不做页表处理
if (next->active_mm) BUG();
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next, this_cpu);
} else {
if (next->active_mm != mm) BUG();
switch_mm(oldmm, mm, next, this_cpu);//如果是用户进程,切换页表
}
if (!prev->mm) {
prev->active_mm = NULL;
mmdrop(oldmm);
}
}
/*
* This just switches the register state and the stack.
*/
switch_to(prev, next, prev);
__schedule_tail(prev);
same_process:
reacquire_kernel_lock(current);
if (current->need_resched)
goto need_resched_back;
return;
}
switch_mm中是进行页表的切换,即将下一个的pgd的开始物理地址放入CP15中的C2寄存器。进程的pgd的虚拟地址存放在task_struct结构中的pgd指针中,通过__virt_to_phys宏可以转变成成物理地址。
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk, unsigned int cpu)
{
if (prev != next)
cpu_switch_mm(next->pgd, tsk);
}
#define cpu_switch_mm(pgd,tsk) cpu_set_pgd(__virt_to_phys((unsigned long)(pgd)))
#define cpu_get_pgd()\
({\
unsigned long pg;\
__asm__("mrc p15, 0, %0, c2, c0, 0"\
: "=r" (pg));\
pg &= ~0x3fff;\
(pgd_t *)phys_to_virt(pg);\
})
switch_to()完成进程上下文的切换,通过调用汇编函数__switch_to完成,其实现比较简单,也就是保存prev进程的上下文信息,该上下文信息由context_save_struct结构描述,包括主要的寄存器,然后将next的上下文信息读出,信息保存在task_struct中的thread.save中TSS_SAVE标识了thread.save在task_struct中的位置。
/*
* Register switch for ARMv3 and ARMv4 processors
* r0 = previous, r1 = next, return previous.
* previous and next are guaranteed not to be the same.
*/
ENTRY(__switch_to)
stmfdsp!, {r4 - sl, fp, lr}@ Store most regs on stack
mrs ip, cpsr
strip, [sp, #-4]!@ Save cpsr_SVC
strsp, [r0, #TSS_SAVE]@ Save sp_SVC
ldrsp, [r1, #TSS_SAVE]@ Get saved sp_SVC
ldrr2, [r1, #TSS_DOMAIN]
ldrip, [sp], #4
mcr p15, 0, r2, c3, c0@ Set domain register
msr spsr, ip@ Save tasks CPSR into SPSR for this return
ldmfdsp!, {r4 - sl, fp, pc}^@ Load all regs saved previously
struct context_save_struct {
unsigned long cpsr;
unsigned long r4;
unsigned long r5;
unsigned long r6;
unsigned long r7;
unsigned long r8;
unsigned long r9;
unsigned long sl;
unsigned long fp;
unsigned long pc;
};
-
 热敏电阻温度阻值查询程序2024年11月13日 74
热敏电阻温度阻值查询程序2024年11月13日 74 -
C99语法规则2024年11月16日 675
-
 FreeRTOS 动态内存管理2024年11月12日 448
FreeRTOS 动态内存管理2024年11月12日 448 -
一款常用buffer程序2024年11月06日 88
-
 1602液晶显示模块的应用2012年08月03日 192
1602液晶显示模块的应用2012年08月03日 192 -
GNU C 9条扩展语法2024年11月18日 261
-
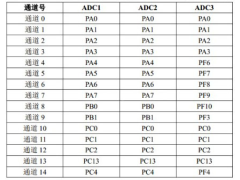 如何实现STM32F407单片机的ADC转换2024年11月15日 300
如何实现STM32F407单片机的ADC转换2024年11月15日 300 -
 STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
STM32使用中断屏蔽寄存器BASEPRI保护临界段2024年11月15日 195
-
C99语法规则2024年11月16日 675
-
 51单片机LED16*16点阵滚动显示2012年09月05日 664
51单片机LED16*16点阵滚动显示2012年09月05日 664 -
FreeRTOS 动态内存管理2024年11月12日 448
-
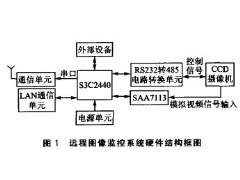 ARM9远程图像无线监控系统2012年07月03日 424
ARM9远程图像无线监控系统2012年07月03日 424 -
 用单片机模拟2272软件解码2012年09月06日 300
用单片机模拟2272软件解码2012年09月06日 300 -
如何实现STM32F407单片机的ADC转换2024年11月15日 300
-
 新颖的单片机LED钟2012年08月06日 278
新颖的单片机LED钟2012年08月06日 278 -
GNU C 9条扩展语法2024年11月18日 261